
Organizations depend on precise and prompt information to enhance their decision-making processes. Data does not become useful the moment it is collected. It must move through several stages before it can support business goals. This complete journey is known as a data pipeline. Understanding how data pipelines work helps beginners see how raw information is transformed into valuable insights. If you want to build a strong foundation in this field, you can explore Data Science Courses in Bangalore at FITA Academy to develop practical skills for future growth.
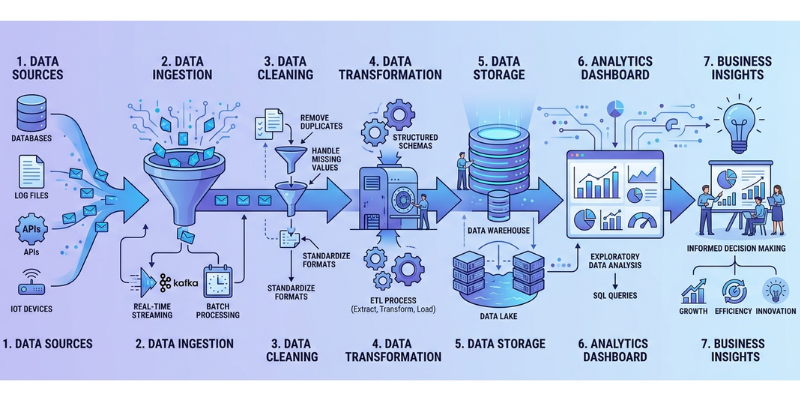
A data pipeline is a sequence of processes that collect, move, transform, and store data. It acts like a pathway that carries data from its source to its final destination. These sources can include websites, applications, sensors, databases, and many other systems. The destination may be a data warehouse, analytics platform, or reporting dashboard.
The Data Collection Stage
Every data pipeline begins with data collection. At this stage, information is gathered from one or more sources. Businesses often collect customer information, sales records, website activity, and operational data. The quality of collected data plays a major role in the success of the entire pipeline.
Different sources may generate data in different formats. Some data may be structured and organized in tables, while other data may be unstructured, such as text documents or images. A well-designed pipeline can handle multiple types of data efficiently.
Data Ingestion and Movement
Once data is collected, it needs to be transferred to a central location. This process is known as data ingestion. Data can move in batches at scheduled intervals or flow continuously in real time.
The main goal of data ingestion is to ensure that information reaches the storage system reliably. During this stage, organizations focus on maintaining data accuracy and preventing data loss. Effective ingestion helps businesses access the latest information whenever it is needed.
Data Transformation and Cleaning
Raw data is rarely ready for analysis. It often contains errors, duplicates, missing values, or inconsistent formats. Data transformation is the process of preparing data for meaningful use.
Cleaning activities may include correcting mistakes, removing duplicate records, and standardizing formats. Transformation may also involve combining data from multiple sources or creating new fields that provide additional insights. These steps improve data quality and make analysis more reliable. To gain hands-on experience with these important processes, you may consider a Data Science Course in Hyderabad and strengthen your understanding through practical projects.
Data Storage and Management
After transformation, data is stored in systems that allow easy access and analysis. Organizations choose storage solutions based on their business needs and the volume of data they manage.
Proper storage helps maintain security, scalability, and performance. It also ensures that authorized users can retrieve information when needed. Good storage practices support reporting, business intelligence, and machine learning applications.
Monitoring and Maintenance
A data pipeline requires continuous monitoring to perform effectively. Issues such as missing data, slow processing, or system failures can affect results. Monitoring tools help identify problems before they become major challenges.
Regular maintenance keeps the pipeline running smoothly. Teams often review performance, update processes, and improve efficiency over time. This ongoing attention helps maintain trust in the data being delivered.
Why Data Pipelines Matter
Data pipelines are essential components in contemporary organizations. They automate repetitive tasks, reduce manual effort, and improve the speed of data delivery. Companies can make quicker and better-informed choices when dependable data is easily accessible.
Well-designed pipelines also improve consistency across departments. Everyone works with the same information, reducing confusion and supporting better collaboration.
Understanding data pipelines from end to end is an essential step for anyone entering the field of data science. From data collection and ingestion to transformation, storage, and monitoring, each stage contributes to turning raw information into valuable business insights. As organizations continue to depend on data for decision-making, knowledge of data pipelines will remain a highly valuable skill. If you are ready to advance your expertise, join a Data Science Course in Ahmedabad and continue building your professional capabilities.

